

The Fluid Dynamics of Message Personalization
Making a personalization map that’s ready to handle the growing complexity of our users' needs


Over the weekend, I had some neighbors over for a barbecue. One of them works in computational fluid dynamics, and as we chatted about his work, something clicked with some refactoring we’ve conducted recently at Aampe.
He explained that in his field, the cost (both in computational complexity and actual dollars) of observing real-world fluid dynamics is so high that it's often more accurate to work with computational models rather than conduct physical tests. At first glance, this seems counterintuitive. Surely real-world experiments would yield more accurate data, right? Well, not exactly. The massive scale of fluid dynamics experiments makes gathering accurate data prohibitively expensive. Imagine the number of sensors you'd need to measure fluid impact on even a moderately sized surface. Now, think about the precision required in each of those sensors and the computational power needed to crunch all that data. You’d need a budget that even NASA might flinch at.
When we have a solid understanding of how a system works on a small scale, we can often extrapolate that understanding to larger scales or different scenarios—no expensive, full-scale experiment required.
This reminded me of a recent refactor we conducted on a portion of the Aampe codebase.
The Refactor: Aampe’s Personalization Map
In Aampe, users write messages that include placeholder sections we call Variants. Within each Variant, users can specify a number of Alternates. For instance, a user might create a "greeting" Variant with Alternates like "Welcome to the team!", "Welcome aboard," and "Welcome to the family." When Aampe’s Agents generate a message to send to a specific user, they select one Alternate per Variant to customize the message. Each Alternate is tagged with labels that describe its qualities. For example, the Alternates above might be labeled "Exciting," "Casual," and "Cozy."
Variants also have types indicating their purpose in the message. For example, the message above contains a Greeting Variant, but we also support other types like Call To Action, Value Proposition, Tone, and Offering (among others). Offerings are particularly core to Aampe messages, as they help drive user engagement. We combine Offerings with other variants to fully personalize each message.
Our Personalization Map feature allows users to see how much coverage different variant labels have relative to each Offering label. If Offering A performs well for a larger subset of users than Offering B, and Value Proposition A only ever appears alongside Offering B, then it will look like the value proposition performs poorly only because it was never given the chance to feature alongside the more popular offering. The Personalization Map lets you ensure that you have even coverage of labels across all offerings.

The Original Personalization Map
The software development adage “make it work, make it right, make it fast” applies especially in startups, where our goal is often to get a feature in front of customers quickly, so we can determine how much value it provides, before we start to optimize it. Such was the case with the Personalization Map, where our first pass at the calculation leaned more towards speed of development and developer comprehension than pure performance.
The original Personalization Map worked by taking all Variants and Alternates for a message, generating every possible combination, looking at the labels attached to each combination, and incrementing a count for relevant combinations. For example, if we were creating a map of Offering > Tone labels, and the full set of generated message combinations contained 3 instances where a message contained both a Tone Alternate labeled "Exciting" and an Offering Alternate labeled "Exclusivity," the resulting map would look like this:

This approach worked fine for messages with a relatively small number of possible combinations, but when customers started creating messages with millions or even tens of millions of combinations, the approach simply didn’t scale. The cost of producing and then observing the entire message set became too computationally expensive to be useful. Fortunately, we didn’t need to go to those lengths.
We already know the rules for how message sets are generated: select one Alternate per Variant and populate them within the message body. So, instead of generating and observing every possible message, we could predict the properties of those messages perfectly—without breaking the bank.
The New Personalization Map
Let’s look at a scenario to see how this plays out. Suppose we have the following message:
"Welcome to the team! We’re happy you joined. Check out the latest blog posts here."
In this message, the phrases correspond to the following types:
"Welcome to the team!" (Greeting)
"We’re happy to have you." (Tone)
"Check out the latest blog posts here." (Offering)
Each Variant has the following Alternates, with labels specified in parentheses:
"Welcome to the team!" (Familiarity), "Thanks for joining!" (Appreciation), "Welcome aboard!" (Casual)
"We’re happy to have you." (Happy), "It’s nice to meet you." (Polite), "Let’s get started." (Active)
"Check out the latest blog posts here." (Novelty), "Find your teammates here." (Connection), "Fill out your profile now." (Personal)
To calculate the Personalization Map for Offering and Greeting, we gather all the labels attached to the Greeting Variant within the message and their counts: Familiarity (1), Appreciation (1), Casual (1).
Next, we calculate how often each label will appear in the overall message set, expressed as a value from 0 to 1. We’ll call this value Coverage. It’s calculated by taking the count for each label and dividing it by the number of Alternates in the Variant: Familiarity (0.3333), Appreciation (0.3333), Casual (0.3333).
We do the same for each Offering label, which gives us these Coverage values: Novelty (0.3333), Connection (0.3333), Personal (0.3333).
For each combination of Offering and Greeting labels, the number of messages containing that combination is equal to the overall message count multiplied by Coverage for the Offering and Coverage for the Greeting. In other words: message_count * offering_coverage * greeting_coverage.
Since the overall message count for this message is 27 (3 Greetings x 3 Tones x 3 Offerings), the personalization map looks like this:

Not exactly edge-of-your-seat thrilling: everything is the same. Let’s spice things up by adding another Familiarity Alternate to the Greeting Variant:
"Welcome to the team!" (Familiarity), "Hello there!" (Familiarity), "Thanks for joining!" (Appreciation), "Welcome aboard!" (Casual)
Now, the values change to:
message_count: 36
familiarity_coverage: 0.5
appreciation_coverage: 0.25
casual_coverage: 0.25
The Coverage for Offering labels remains the same, so the map now looks like:

That makes sense. We’ve doubled the number of messages with the Familiarity label, while the counts for the other labels stay the same—even though their Coverage value has changed. This is because the total number of possible messages increased with the new Alternate.
Handling the Same Label Across Variants
Now, let’s complicate things a bit by adding another Greeting Variant:
"Welcome to the team!" (Greeting)
"Your account is set up." (Greeting)
"We’re happy to have you." (Tone)
"Check out the latest blog posts here." (Offering)
The alternates and labels for the new Greeting Variant are: "Your account is set up." (Efficiency), "Your teammates are waiting." (Urgency), and "Everything is ready for you." (Familiarity).
Now we’ll have messages where the same label is duplicated across two Variants. This is interesting because when we calculate Coverage for each Variant, we have to account for messages where the same label appears in both. For example, Familiarity has 0.5 Coverage in Variant 1 and 0.333 Coverage in Variant 2. We can’t just sum these values for the total Coverage because that would result in double-counting.
To avoid this, when calculating Coverage in Variant 2, we eliminate the Familiarity instances from Variant 1. We do this by multiplying the Coverage value for Variant 2 by the inverse of the Coverage for Variant 1. In this case, that gives us 0.333 * 0.5 = 0.166. When we add the Coverage for both variants together (0.5 + 0.166 = 0.666) and multiply that by the total number of messages, we get the correct value of 81 * 0.666 * 0.333 = 18.
The resulting personalization map looks like this:

Message-Level Labels
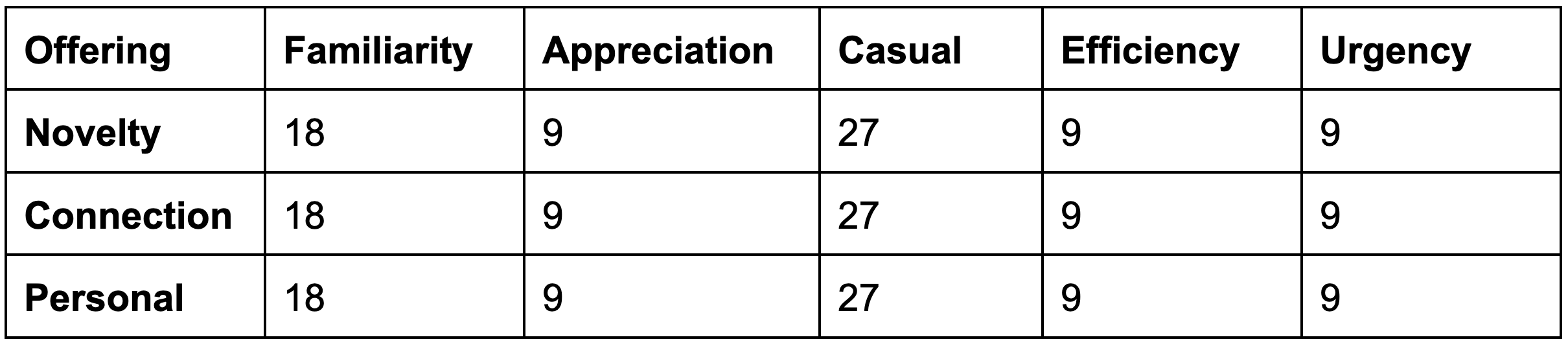
Let’s complicate things further by considering something we haven’t touched on yet: labels applied to an entire Message. When a label is applied at the Message level, every possible message combination uses that label. For example, if we applied a message-level "Casual" label to the scenario above, where the total message count is 81 (or 27 per Offering label), the resulting personalization map would look like this:
Performance Gains
So how much more efficient is the new approach? When the original implementation started succumbing to the scale of our customers’ data, our response time distribution looked like this:

Yes, the P90-99 values are in hours.
With the new implementation, the distribution looks like this:

Still not blazingly fast at the higher ranges. There are likely additional optimizations we can make for customers with large numbers of messages, since we run a calculation per message, but it’s now back in a decidedly usable range. The performance improvement works out to:

Wrapping It Up
So, what did my neighbor’s fluid dynamics lesson teach us? Just like in computational fluid dynamics, where observing every variable in a real-world experiment is impractical, we realized that we didn’t need to produce every possible message. Instead, we leveraged the underlying rules of message generation to predict the outcome. The result? A personalization map that’s more efficient, scalable, and ready to handle the growing complexity of our users' needs.
Next time you find yourself bogged down by the sheer volume of possibilities, remember: sometimes, it's not about observing every outcome but understanding the rules that generate them. And who knows, maybe a backyard barbecue can spark your next big breakthrough, too.